How is autocorrect different than Transformer models?
When you type on your phone and see words magically suggested, you might think it's AI — but it's not the same kind you hear about with "ChatGPT" or "Transformers." — ChatGPT.
I think people would commonly associate transformers with the autocorrect on their phones, and I think it's pretty reasonable to do so. Both have capabilities to write coherent english(or almost every language) sentences which have meaning and can predict the next word depending on the context of the sentence(even though one of these models are absurd but let's try to work with it, that's what we're here for). Let's see how they're both different, and how can maybe do something to change that and find a way to make autocorrect almost work like a transformer. code on my github (https://github.com/ajeebtech/autocorrect)
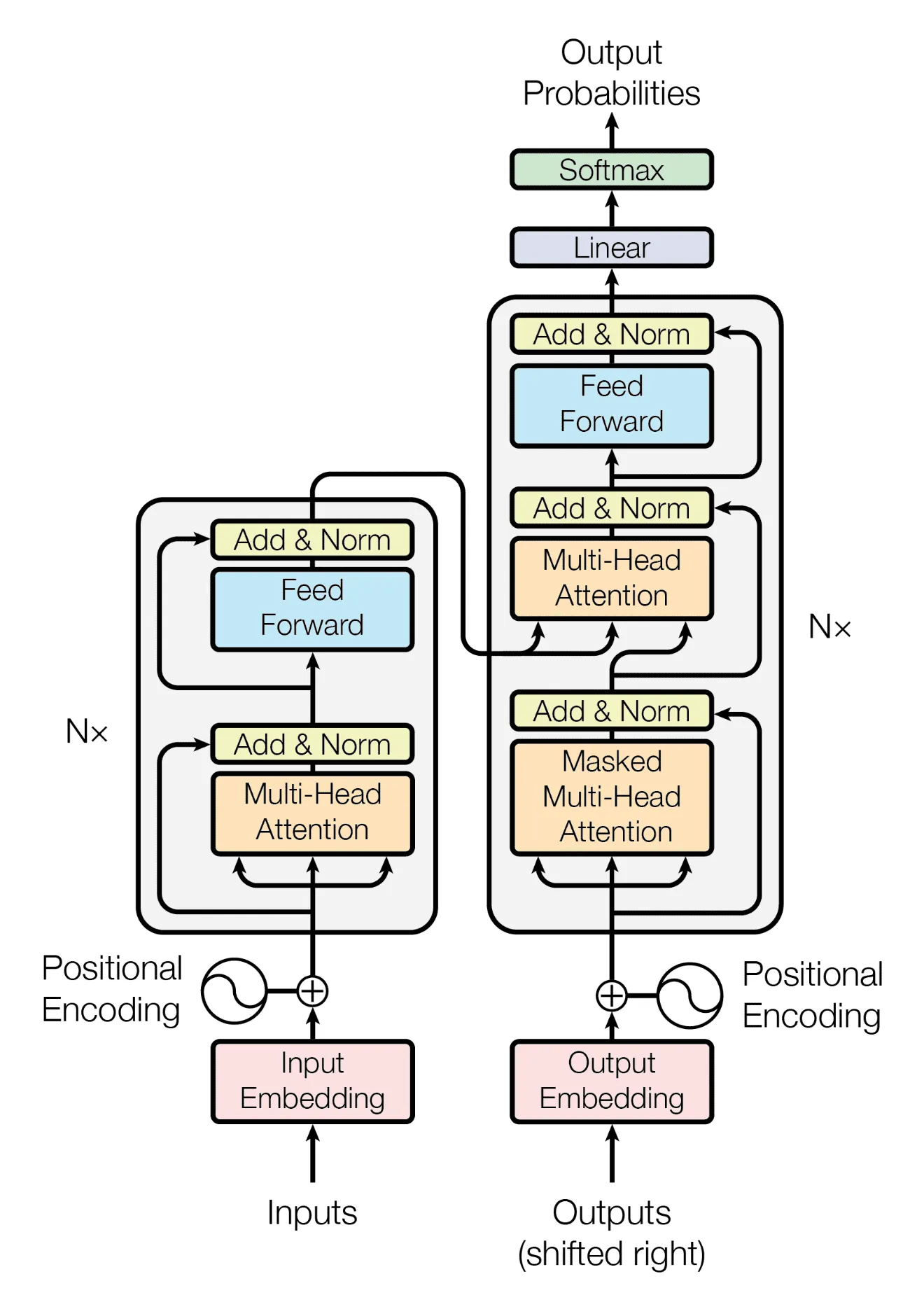
The Transformer from Attention is all you need(arxiv.org/abs/1706.03762) You see the keyboards that use auto correct on your phones like Gboard and Microsoft SwiftKeyboard are not open source and so i can't get one on my trusty macbook to fine tune and implement stuff, but what we can do is, replicate one to the brim and then try to construct it again with the transformer features, let's do that right now.
So autocorrect basically has features like
- Fixing typos, finding words that they actually meant. A qwerty based-proximity-spell corrector.
- Finding the next most probable words and displayed are the top 3 predictions on your keyboard.
- Auto-completing sentences.
- And that's about it.
So I got my chatgpt on work, we built a qwerty proximity using some regex and we're using https://norvig.com/big.txt as context.
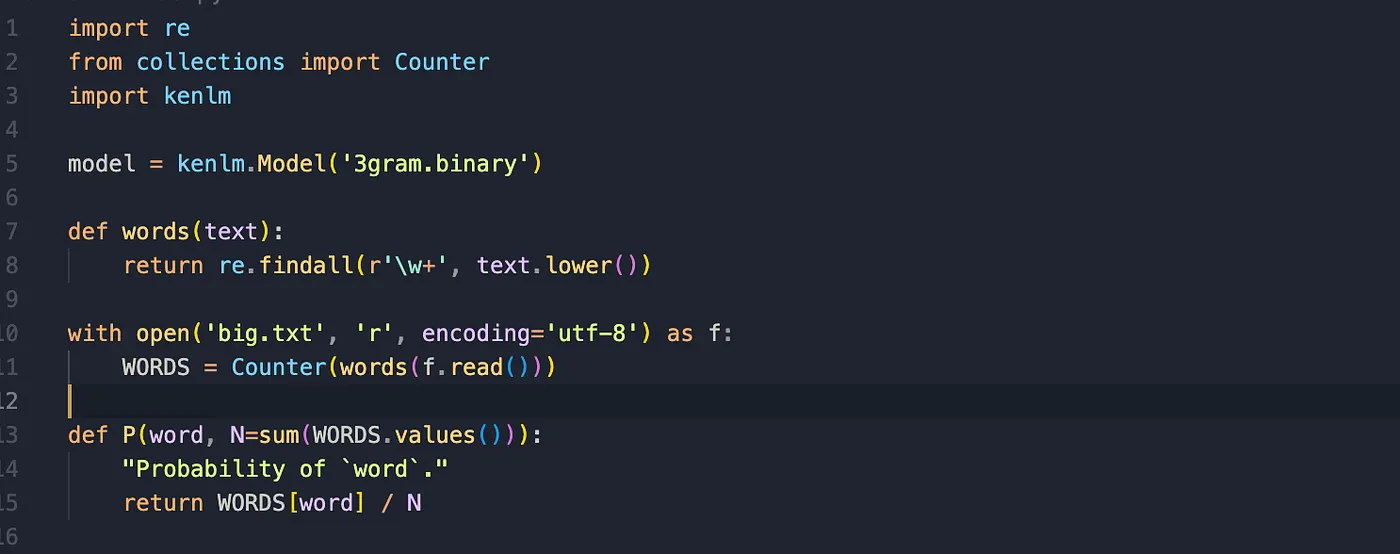
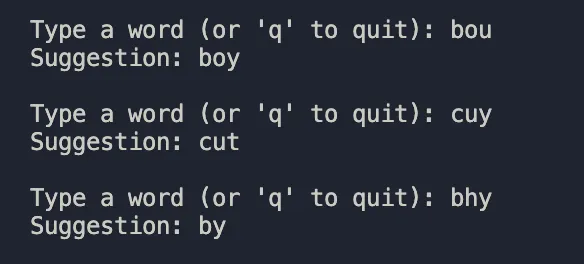
Counter basically just counts the frequency of the words to help the model find the most probable candidates for the word we wanted to mean using with the qwerty spell corrector.
works! The next thing that we require is, context based probabilities! I'll be using the KenLM to decipher the next word's probability, you could just think of it it like a encoder which just assigns probabilities to tokens without actually encoding vectors or anything with a pretty weak decoder, it's nothing like a neural net, it's purely statistical. This is the heuristic + statistical based algorithm at work
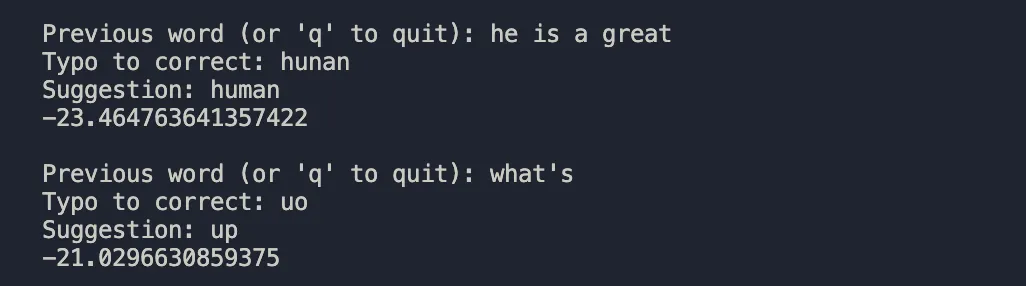
the suggestion is followed on by the score the model had for that word in that context. i could have done a better job. Now I want to get the 3 most probable words I'd want to use after a string. What we have now is our own autocorrect.
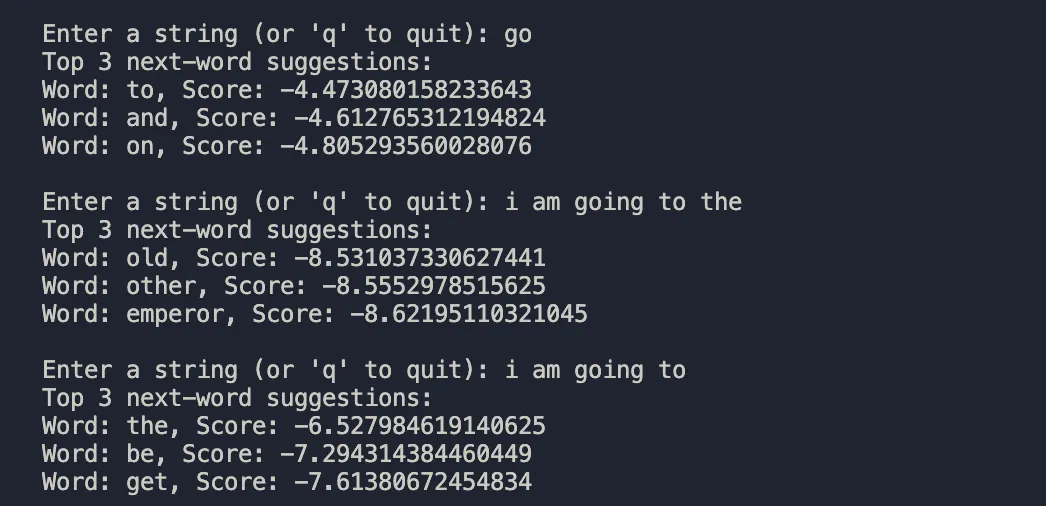
just like your keyboard Now what does this not do well? It can access your entire corpus or your messaging history but it doesn't have attention layers, it doesn't have higher dimensional vector embeddings, it can't produce large paragraphs because it will just keep repeating the same phrase over and over again, let me show you what i mean:
"im sorry for the inconvenience caused by mistake I was not able to reach her since we got our board results and i just wish i could hear from her that she's doing great and tell her all the best for your team be the best for your team be the best for your team be the best for your team be the"
It's just gonna repeat the same sentence again and again, it doesn't know what it's doing, (nor do transformers, they just matrice multiply and generate) What can we do to make autocorrect function more like a transformer? Let's work on that now. Let's set up a system with PyTorch and build a transformer-based model using the token embeddings we talked about earlier to generate something concrete and meaningful. Of course, we'll need way more data to get outputs that are actually coherent — that's one of the tradeoffs with this technique. But the advantage is, it enables you to generate full, context-aware text messages, according to the context, similarly like in the PokéChamp paper(arxiv.org/pdf/2503.04094), where the trainer(the LLM), operates differently to different type of players using player action sampling, in our case, a different situation, where you need to handle issues according to the context you're in, conversation with that guy who just sends you 20 reels a day, talking to your boss, meeting up with your date etc. . This was an idea I used to have, an assistant that just replies to messages like I always do, a set base of rules, a way of making jokes, saying yes to stuff I'd generally say, basically my own Jarvis.
While I will not be able to make my Jarvis today, but I think it could be a great idea, it's for sure one of my future projects. Let's get back to training our transformer. Well back to training our transformer over the same corpus we used for the autocorrect replica, our transformer takes the elements of positional encoding, token embedding, logits, forward passes and uses the https://norvig.com/big.txt as corpus again. Gosh it's gonna take a long while to train this thing.
After 6 hours of training this model while I was playing sleeping, here are the results. With more corpus and a hell lot of encoding layers, we could get sentences with appropriate context, maybe I shouldn't have done this with just one epoch, (one epoch took me 6 hours)

I repeat, this does not work well for data this less, 6mb being the corpus for this, this is an example of an overfitted model, a result of what happens when you train it for too less epochs and on a tiny dataset. Well that was it for my second ever blog thank u for reading through, hope we learnt something new today.